
非結構化資料分析-社群媒體文字分析
Unstructured Data Analytics -Social
Media text Analytics
本團隊研究特色在於利用自然語言處理(natural language processing)、文字探勘(text
mining)、語意嵌入(semantic embeddings)與深度學習(deep learning)等技術,發展情感分析(sentiment analysis)相關應用,如:輿情分析、口碑分析、品牌調查等。相關研究成果說明如下:
1. 維度型情感分析(dimensional
sentiment analysis):
情感表示法可區分為類別型(categorical)及維度型(dimensional)兩種。類別型是將情感表示為數個類別(如:正負兩類),而維度型是以多個維度表示情感,如圖一之Valence-Arousal (VA)二維平面,其中Valence代表正面與負面的程度,數值越大越正面,越小越負面,Arousal代表激動(excited)程度,數值越大越激動,越小則越平靜,圖中任一點表示某篇討論文章之情感VA值。相較之下維度型表示法能夠提供更為細緻的情感分析,故本團隊除探討傳統類別型表示法之外,亦投入維度型表示法相關研究。
 |
圖一:維度型表示法之一例
維度型情感分析研究成果說明如下:
l 以跨語(cross-lingual)資源預測情緒維度值:維度型情感分析近年來逐漸受到重視,但中文之情緒維度資源仍相當缺乏,以情緒詞典為例,中文相當稀少,故2011年有研究嘗試以線性迴歸將英文情緒詞典裡的維度值映射到中文詞典,而本團隊提出以線性迴歸Locally weighted線性迴歸改進其方法(圖二),並發表於情感分析領域最重要的研討會ACII 2015。
 |
圖二:以跨語資源預測情緒維度值之結果
|
l 以單語(mono-lingual)資源預測情緒維度值:有鑑於使用跨語資源可能因文化之差異造成較大的誤差,因此,使用相同語言的資源實有其必要性。故本團隊自行建立一套1,653詞之中文情緒維度詞典,已獲得語言資源最重要的國際會議LREC 2016接受 (圖三)。並且我們也利用這套詞典,提出加權圖模型(weighted graph model)來預測詞彙情緒維度值,效果較現有方法優,並已獲自然語言處理領域最重要的國際會議ACL 2015接受。
 |
圖三:(a)CVAW中文情緒維度詞典散佈圖
|
 |
圖三:(b)CVAT中文情緒維度語料庫散佈圖
|
l 產業應用價值:運用情感分析技術可從大量的社群資料中獲取民眾對於某個事件、品牌之看法,為輿情分析、口碑分析等應用之關鍵技術之一,近年來已獲政府單位及許多產業高度重視。本團隊以上述技術為基礎,開發一套社群媒體分析平台( http://social.innobic.yzu.edu.tw/),成果詳見圖四。
 |
圖四:(a)聲量趨勢
|
 |
圖四:(b)德國汽車大廠"福斯事件"發生前後社群討論口碑變化
|
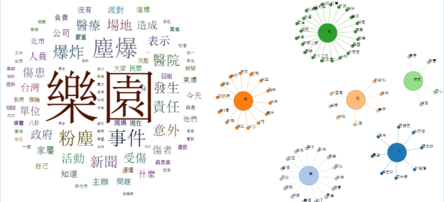 |
圖四:(c)社群討論內容概況
|
2. 規則式意見句子識別:
情感分析也可以利用搜尋引擎的概念來進行,也就是由使用者輸入想要查詢的資訊需求,稱為查詢問句(query)或關鍵字,例如,輸入“油耗”來搜尋汽車評論中有討論車輛油耗的內容,之後由系統自動檢索討論目標產品特徵的意見句子,這個過程就稱為意見句子識別。意見句子識別效果的關鍵在於查詢問句的品質與完整性,然而使用者通常只會輸入很短的查詢問句,因此侷限了意見句子識別的效果。我們利用類別關聯規則(class association rule)演算法,提出一個半監督式(semi-supervised)的規則式意見句子識別(R-OSI)技術,其架構如圖5。R-OSI技術僅需準備少量(1~3個)關鍵字,與大量未經標註的文集,便可達到優於傳統監督式學習法的效能(表1)。
 |
圖五:規則式意見句子識別技術架構
表1、規則式意見句子識別結果
|

3. 網拍詐欺帳戶偵測:
近年來,隨著互聯網的發達,網路購物已成為重要的採購方式之一。大量的網路交易意味著許多的賺錢機會,自然吸引了許多的賣家在網路上銷售商品。然而,在這眾多的賣家中,也常有不肖人士從事詐欺之行為。若未能有效遏止網路詐欺的發生,將有損一般消費者從事網路購物的信心,進而影響網路市場的發展。因此,如何有效偵測網路詐欺極為重要。網路購物中的買家與賣家構成一巨大的社群網路,而購物網站所累積的龐大交易量也成為大數據重要的應用。如何有效使用拍賣網站中的資料協助偵測網路詐欺的帳戶是一重要的研究課題。
在拍賣網站完成每一筆交易後,買家與賣家都可以給對方一個評價。個別帳戶透過累積正面的評價,可建立其可信賴程度。由於網路拍賣交易過程中,買賣雙方常沒有實體的接觸,買方也通常未能先看到實體商品才下單,因此買賣雙方的可信賴度極為重要。從事網拍詐欺者也深知可信賴度的重要,因此常透過一群同夥互相透過小金額的假交易,互相給對方正面評價,以迅速累積好的可信賴程度,進而方便其後續吸引無辜消費者進行交易。
有鑑於此,利用網拍交易資料中買家與賣家互給評比的資料,擷取出其中重要的特性,以用於偵測詐欺帳戶是目前常用的做法。由於詐欺帳戶需要依賴一群同夥來累積其正面評價,而這群同夥在網拍評價的社群網路資料中,便成為此詐欺帳戶的鄰居(neighbor)。由於這些同夥帳戶在行為模式上常有相似之處,因此利用一個帳戶的所有鄰居帳戶的多樣性(neighbor diversity)來偵測詐欺帳戶是一可行之道。研究文獻[1]利用熵(entropy)的概念來量化neighbor diversity。實驗結果發現透過評價個數或取消交易個數所建立的neighbor diversity都可以比過去文獻的方法(使用k-core或center weight等方式)有更佳的偵測準確度。網拍詐欺帳戶的偵測著重在如何找出重要的特性以區別正常與詐欺帳戶。隨著詐欺手法的推陳出新,偵測方式也必須隨之與時俱進。因此,如何發展自動調適的偵測方式將是後續研究的重要課題。此外,網拍資料內容豐富且龐大,後續還可結合其他資料庫進行多類型的大數據運用。例如,與股市、財經資料結合進行股市與財經指標的預測,或與社群網站、論壇資料結合進行市場的預測。這些議題也是極具潛力的研究課題。
參考資料
[1].Jun-Lin
Lin and Laksamee Khomnotai. Using Neighbor Diversity to Detect Fraudsters in
Online Auction. Entropy. 2014, 16(5), 2629-2641. (SCI)
(本文由本中心非結構化資料分析核心技術Team A團隊提供)
非結構化資料分析-單張影像雨滴去除技術
Unstructured Data Analytics -Single Image-based Rain Removal
Using Sparse Coding
現今行動裝置風行的年代,可隨手拍下周遭景物及人、多數轎車裝有行車紀錄器以確保自身權益、重大交通路口及高速公路都設有監視器監視著交通狀況,社會到處都有攝影鏡頭,多數情況這些攝影鏡頭保有正常的功能,但是難免遇到不可避免的狀況發生,可能會影響到其影像清晰度,例如:光照、天氣等。在此計畫中我們著手處理在下雨天的雨痕所造成雜訊,若是能準確去除影像中的雨痕,不但能更正確的判讀影像的內容,尤其對於應用於交通上的影像有絕對的幫助,交通主管單位的監視器若是不受下雨的影響能更準確的掌握當前的交通狀況,行車紀錄器的鏡頭若是可以不受下雨的影響,保持視線的清晰,可協助駕駛者的行車安全。我們主要提出的方法在於單張影像去雨化的軟體運算處理,不同於以往的研究大部分是影片後製的方法,透過時間軸上的改變去偵測雨滴,進而達到去除雨滴,此種後製的方法並不能達到即時運用的構想,因此我們主要專研於單張影像處理的加強。據我們所知,文獻[1]是首篇提出單張影像去雨議題的論文,在我們研讀過這篇高水準且具創新思維的論文,我們提出一項“景深及聚焦”的概念去提升去雨的準確度及效能。
 |
圖六、運算流程圖
 |
圖七:低頻及高頻影像
|
計算流程如圖六所示,單張影像讀進電腦後,以Guided Filter做邊緣保留的模糊化,如此可以做到最基本的去雨化但是得到的是模糊的影像我們稱作”低頻影像”(圖七左),將原圖與低頻影像相減得到”高頻影像”(圖七右),然後對高頻做重疊式的掃描取patches,此時的資料量非常的龐大,因此我們將取出來的所有得到patches以Sparse Coding做訓練得到字典(Dictionary如:圖八),其中包含1024個代表性的patches,以HoG (Histogramof Gradient)作為特徵用K-means分類器對訓練出的字典做分類,分成雨跟非雨的兩種Sub-Dictionary(DR &
DNR),再用DoD(Difference of Depth)作為特徵對非雨的字典做分類,再次分成兩種Sub-Dictionary (DNR_HD &
DNR_LD)以加快運算速度,後續會再詳細解釋。最後將DNR_LD重建回圖片再加上跟雨角度相似的區域就是我們要的最終的去雨效果。
 |
圖八:低頻及高頻影像
|
DoD(Difference
of Depth)是我們的演算法中主要的貢獻所在,主要是找出影像中聚焦的區域,能在三個部分做有效的加強影像清晰度以及加快運算速度,其計算公式如下以供參考。

第一個加強部分:用DoD找出影像中聚焦的區域(如圖九),對低頻做一個基本的強化,如圖十所示。
 |
圖九:找出影像中聚焦的區域
|
 |
圖十:原本的低頻
& 強化過的低頻
|
第二個加強部分:
在Sparse Coding的程式碼中,有一個參數為Size of the
minibatch,調高會增加大量的運算時間,調低會降低分類的準確率,為了取得平衡點,因此我們先以調低其參數,再分類成DNR_HD & DNR_LD然後將錯誤的分類去除(如圖十一),以達到提升速度卻不失去品質的效果。
 |
圖十一:左上的圖尚未將錯誤去除隱約還有雨的痕跡,而左下的圖是乾淨的
|
第三個加強部分:
利用兩個DoD的權重圖對跟雨角度相似的區域還原,以達到更好的影像清晰度,如圖十二所示。
 |
圖十二:未加強&已加強之比較
|
Sparse Coding原本用來做影像壓縮的技術,在這裡我們用來將影像拆解成雨跟非雨,再去做還原,以達到去雨的效果,其計算式十分複雜,我們提供其中兩個具代表性的方程式以供參考。

對於單張影像去雨的議題,實驗結果如圖十三,我們提供了新的深度及聚焦之概念,應用了稀疏矩陣之字典訓練中拆解還原的技術,也結合多種特徵作為判斷的依據,提升判斷雨或非雨的準確度,完全不同於過去影片後製的方法,提供不同的思維模式及方法,也加強了文獻[1]提出原始的架構所不足之處,研究成果發表於 IEEE Transactions on Circuits and Systems for Video Technology, Vol. 24, No. 8, pp. 1430-1455, Aug. 2014. 未來我們將持續研究以提升影像視覺上的效果及運算之效能,相信若是能達到即時影像的效果必定能有更多方面的應用,未來在雨天影像上的實用性將無可限量。
 |
圖十三:(a)(b)為原始影像;
(c)(d)為文獻[1]之結果;(e)(f)為我們的實驗之結果;其中(f)圖中汽車及街樹都較圖(d)更為清晰
|
參考資料
[1].Li-Wei
Kang and Chia-Wen Lin, “Automatic Single-Image-Based Rain Streaks Removal via
Image Decomposition,” IEEE Transactions on Image Processing, 2011
(本文由本中心非結構化資料分析核心技術Team B團隊提供)
沒有留言:
張貼留言